Rennsimulation
Traning eines Agenten mit Policy Gradient
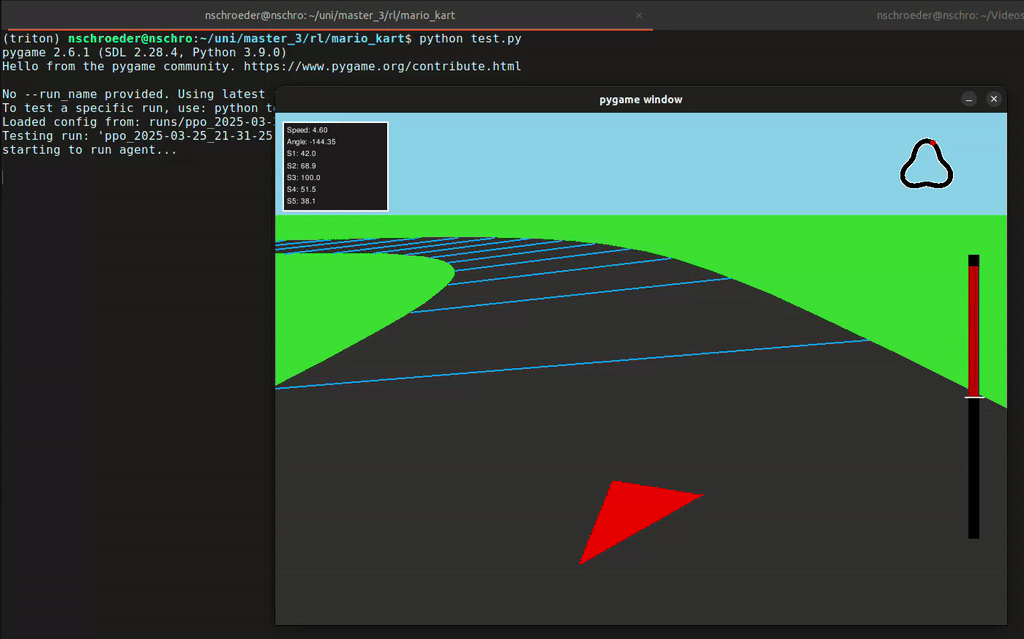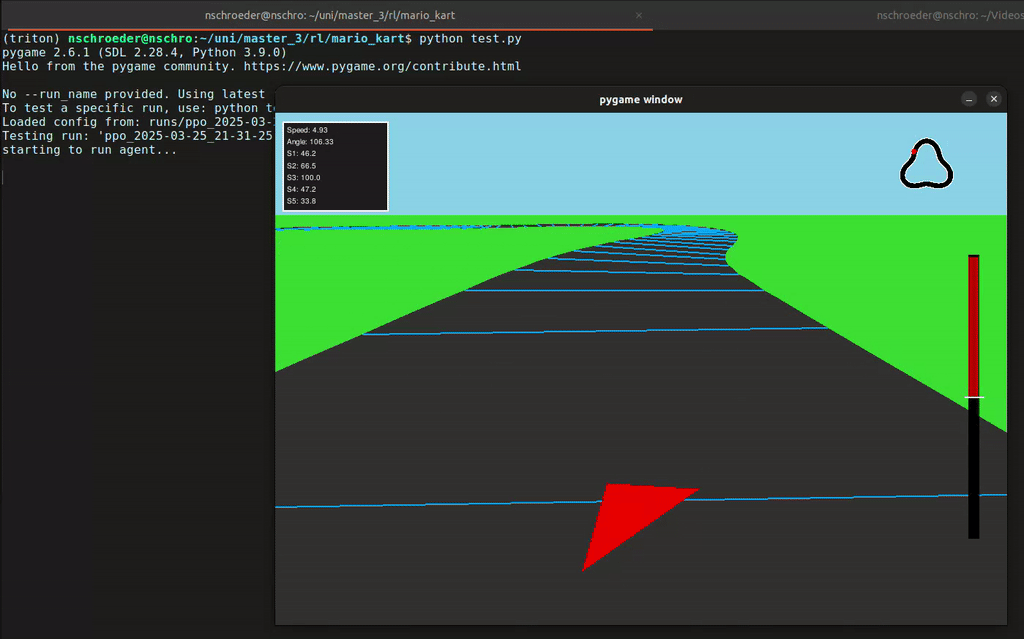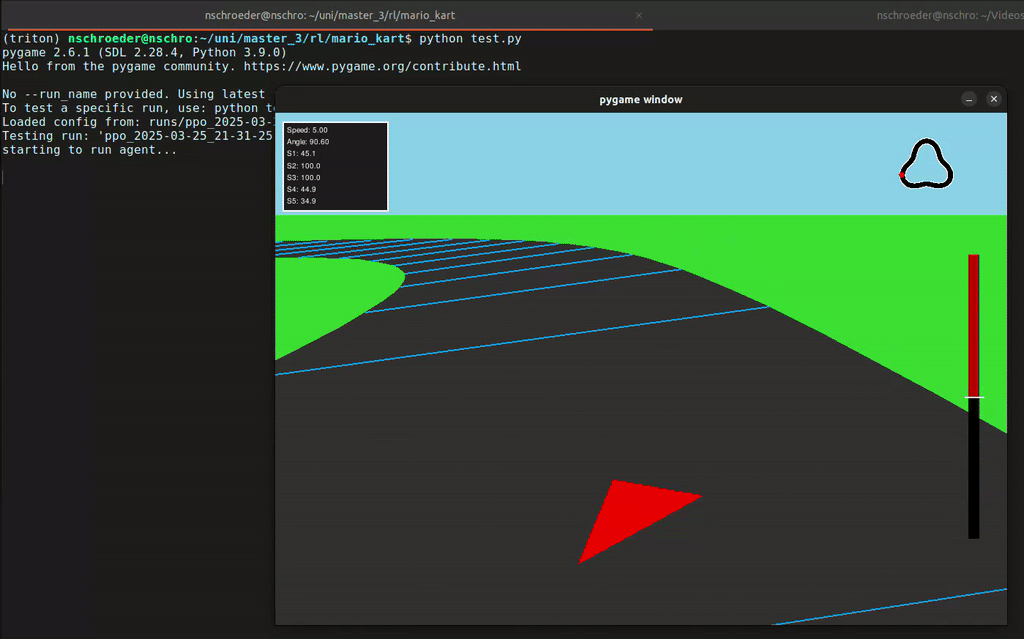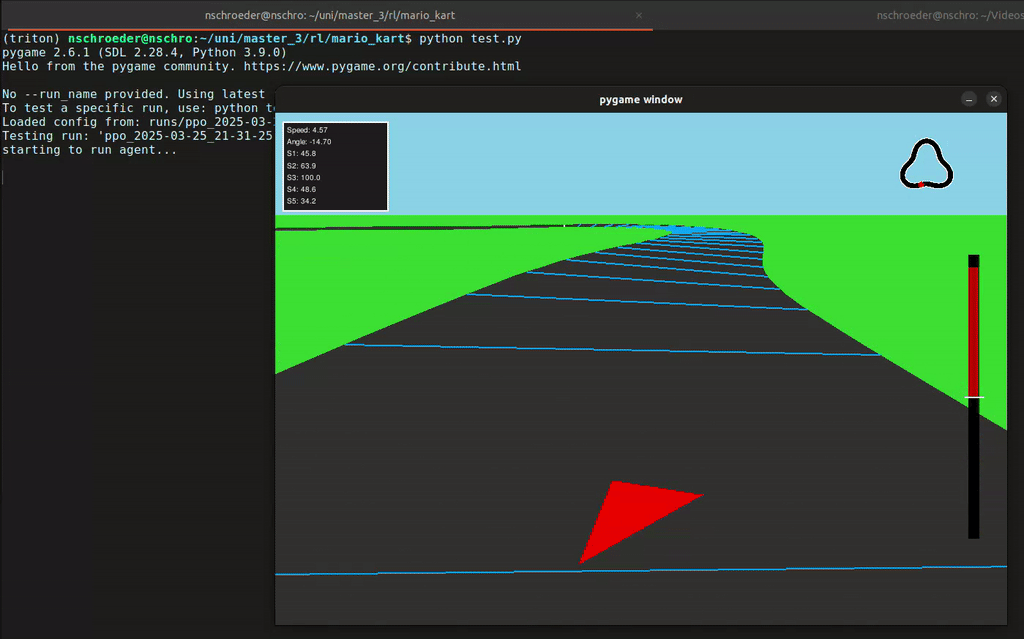
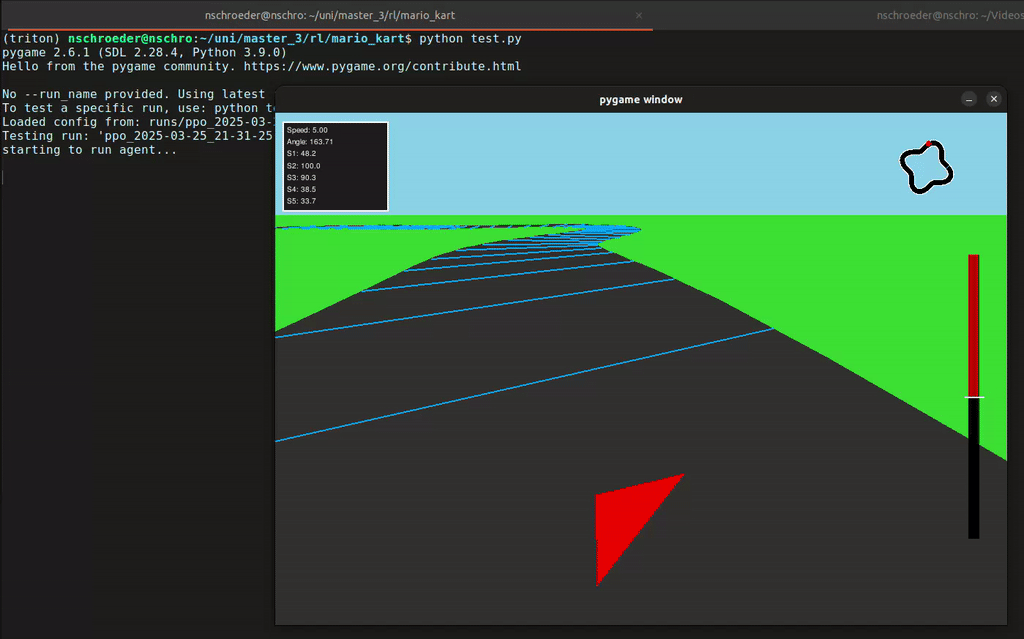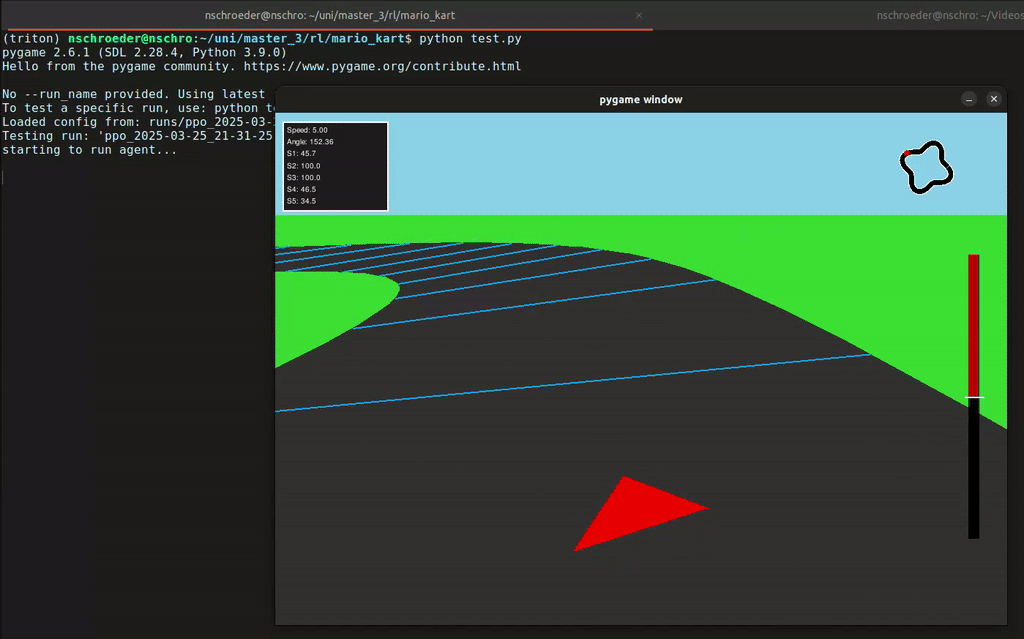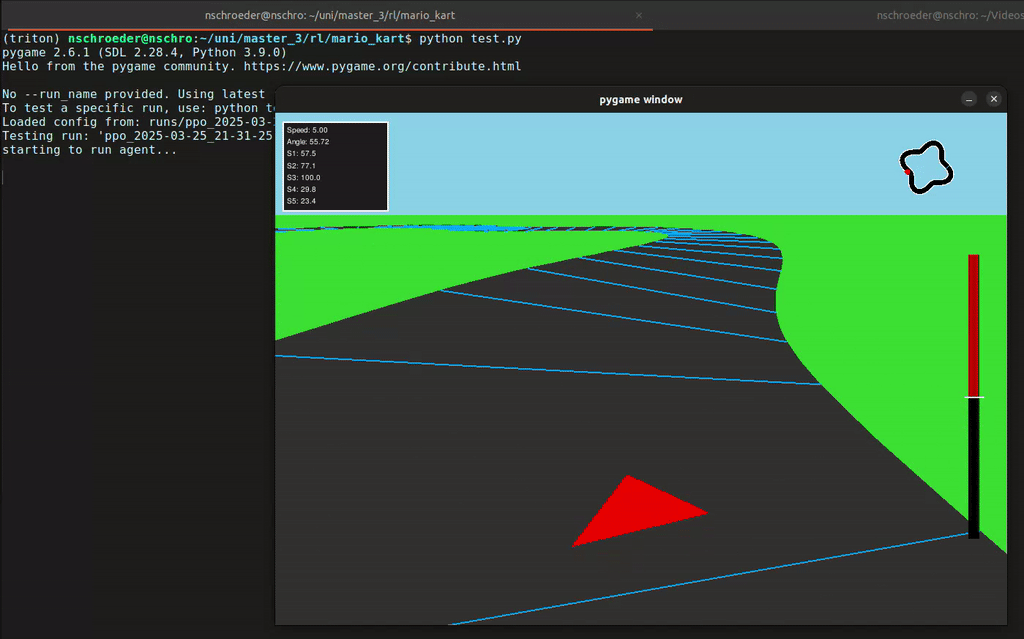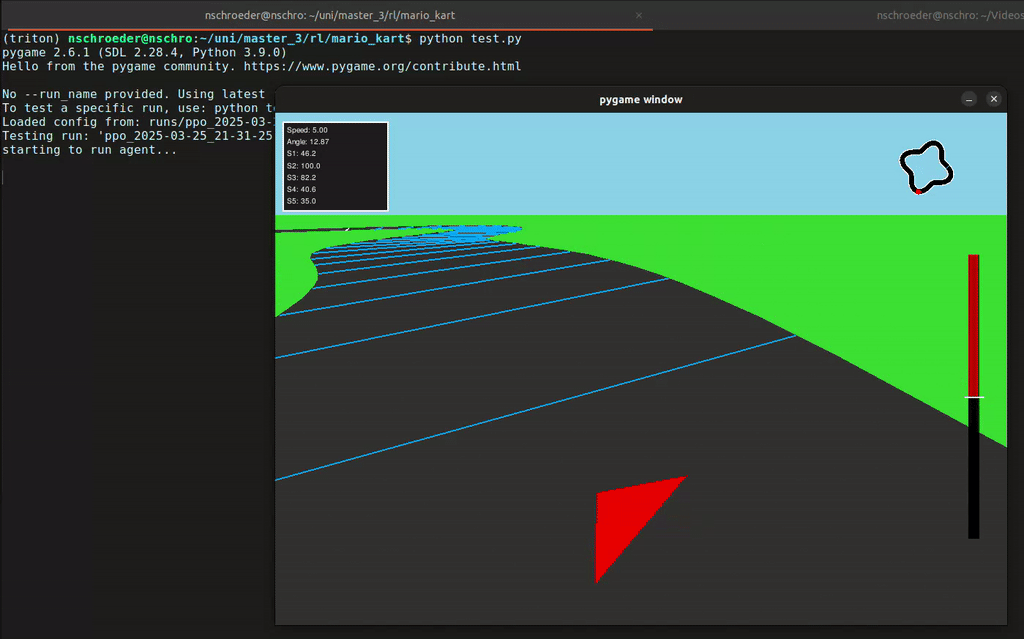
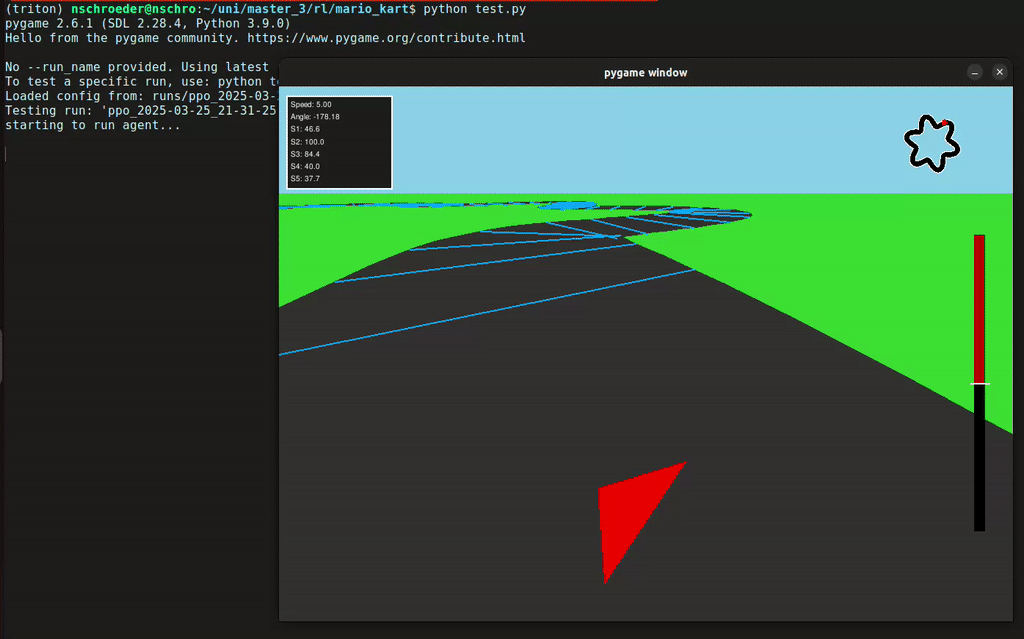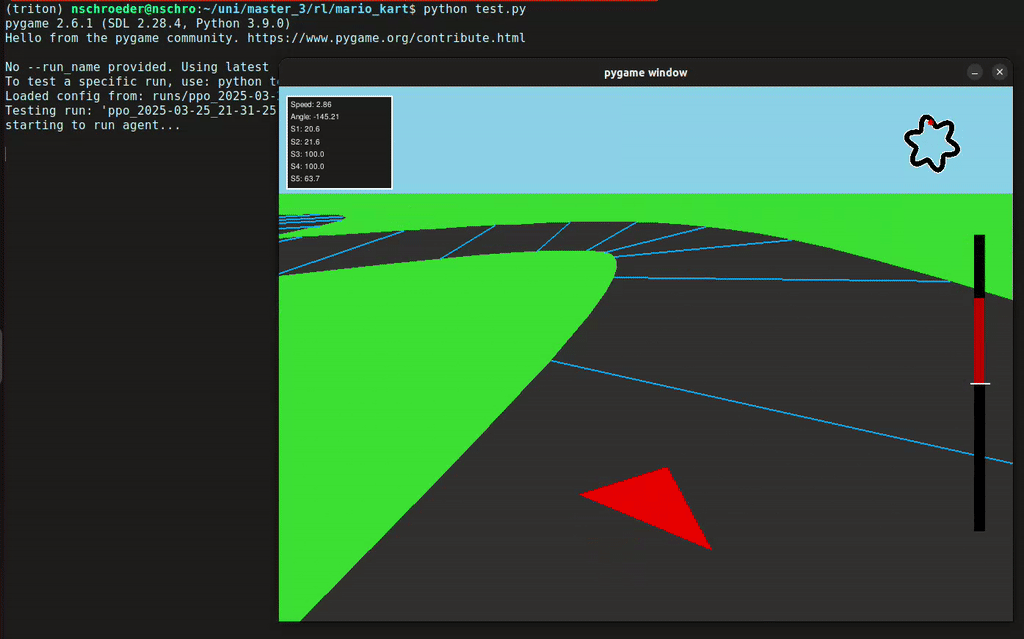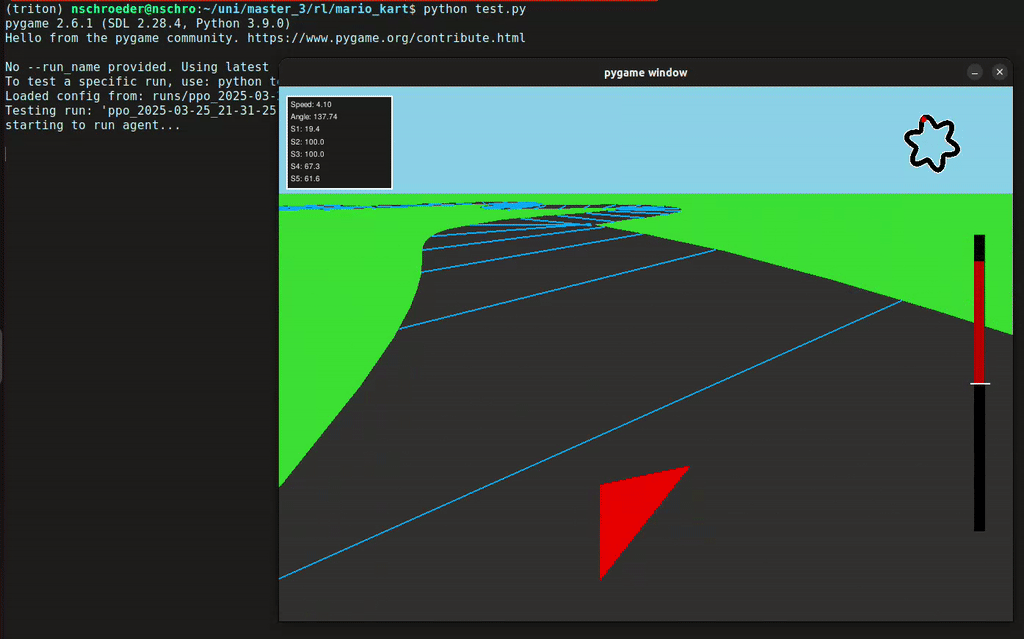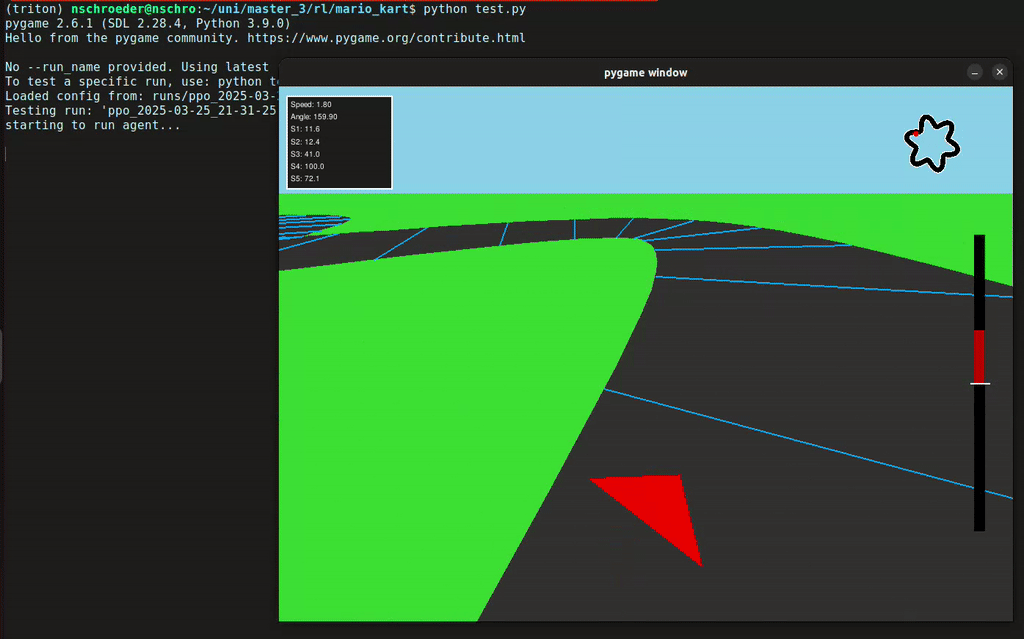
In diesem Projekt hat unsere Gruppe eine Rennumgebung in Python simuliert, in der ein Agent ein Fahrzeug steuern konnte – inklusive Lenkung und Gas geben. Der Agent erhielt von der Umgebung Feedback in Form von Rewards, abhängig von der ausgeführten Aktion. Mithilfe des Reinforcement-Learning-Algorithmus PPO (Proximal Policy Optimization) lernte der Agent, seine Entscheidungen kontinuierlich zu verbessern, um das Auto immer effizienter über die Rennstrecke zu steuern.
Technologien & Tools
- Python
- PyTorch
- Q-Learning
- Policy Gradient - Proximal Policy Optimization (PPO)
Highlights
- Implementierung einer eigenen Reinforcement Learning Umgebung
- Modifikation des Reward-Systems basierend auf den Ergebnissen des Agenten
- 2D- und 3D-Visualisierung der Autorennbahn
- Einbettung des PPO-Algorithmus in die Umgebung
- Arbeit im Team mit drei Personen
Links